01 Jul 2021
Intro
Spiegel Online published 3.590 articles in June 2021. An important event during that time was the soccer EM 2021, which started on June 11 and had a few interesting impacts on the articles.
Articles per Category
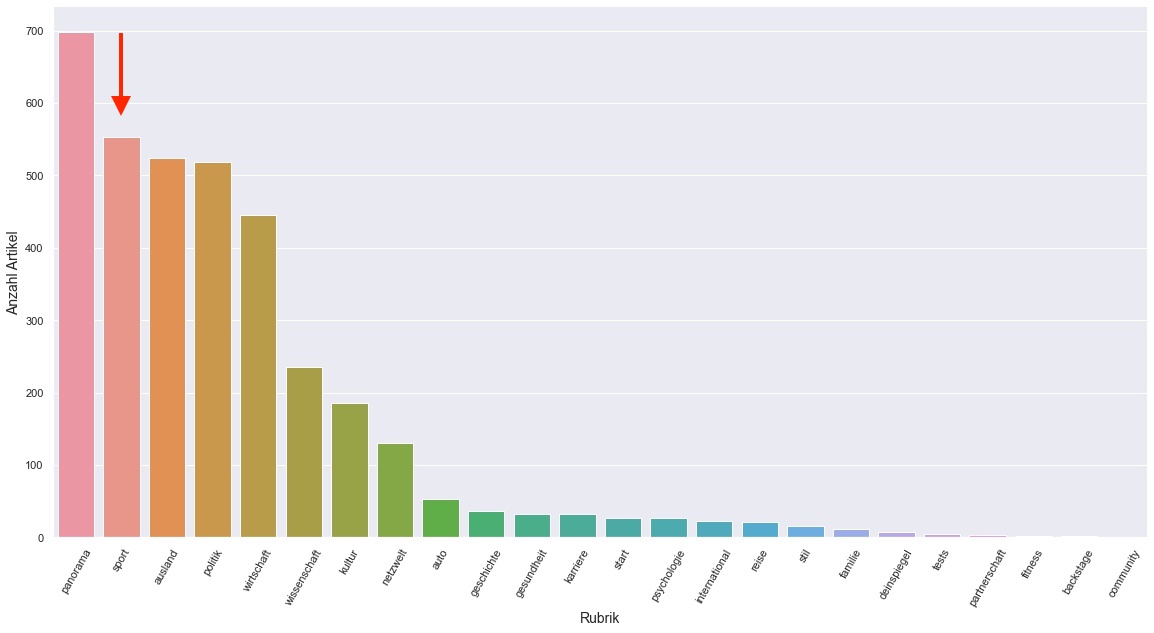
First we will take a look at the overall amount of articles published per category. As expected there’s a significant increase in articles for the Sport category.
Panorama is again the category with the most articles. Overall this month was dominated by Panorama, Sport, Ausland, Politik and Wirtschaft.
The graphic below shows how many Sport articles came out each day in June. We see a strong correlation between the start of the soccer EM on June 11th and the increase of articles per day.
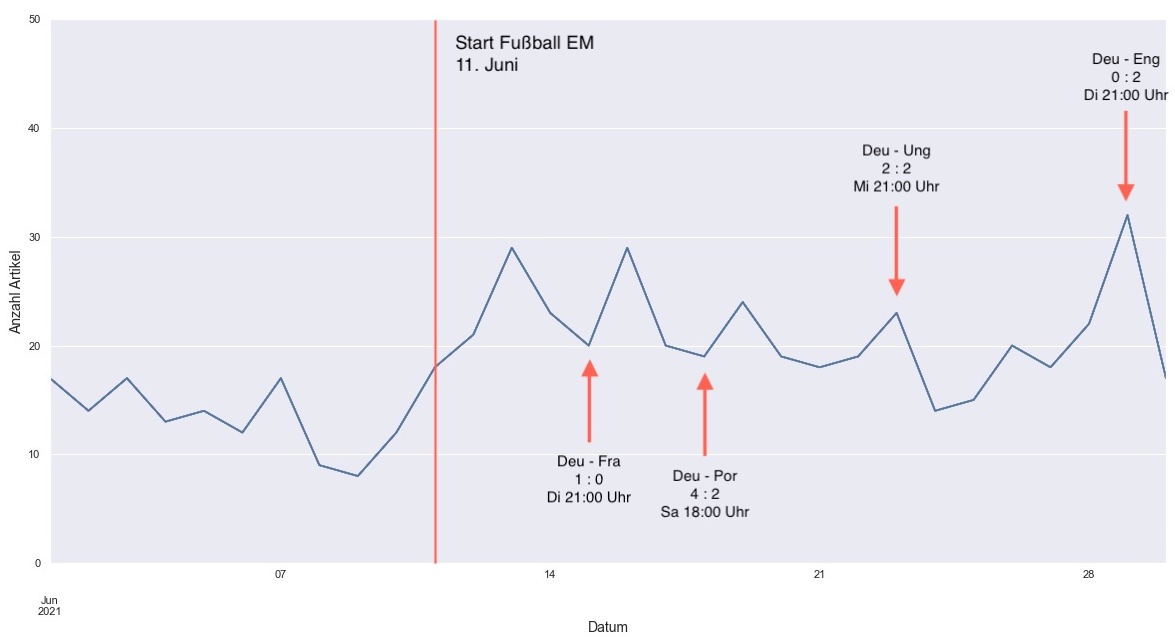
Germany won the first two matches, which caused an increase in articles on the next day. The match on June 23 against Hungary ended with a draw and there’s a drop in articles on the next day.
June 29 is the day with the most articles published during the whole month. The match against England ended with a lose and the article count on the next day drops by almost 50%
Sentiment per Category
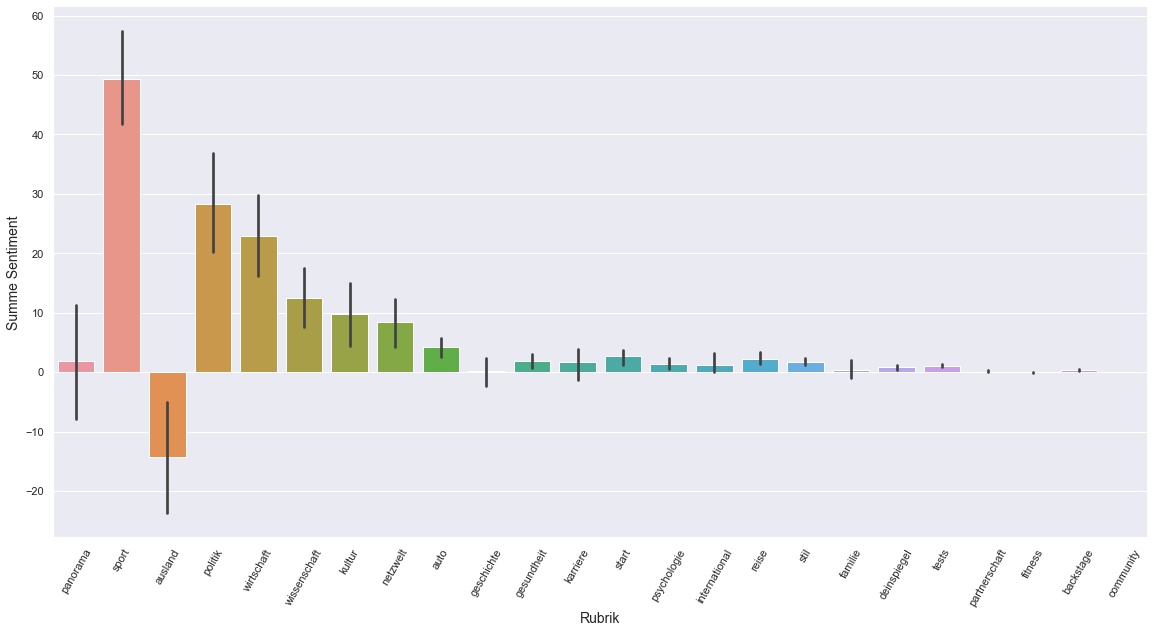
This month Ausland is the only category with mostly negative articles. Again Sport is by far the most positive category, although not as strong as last month where it had a score of over 100, compared to this month with barely 50.
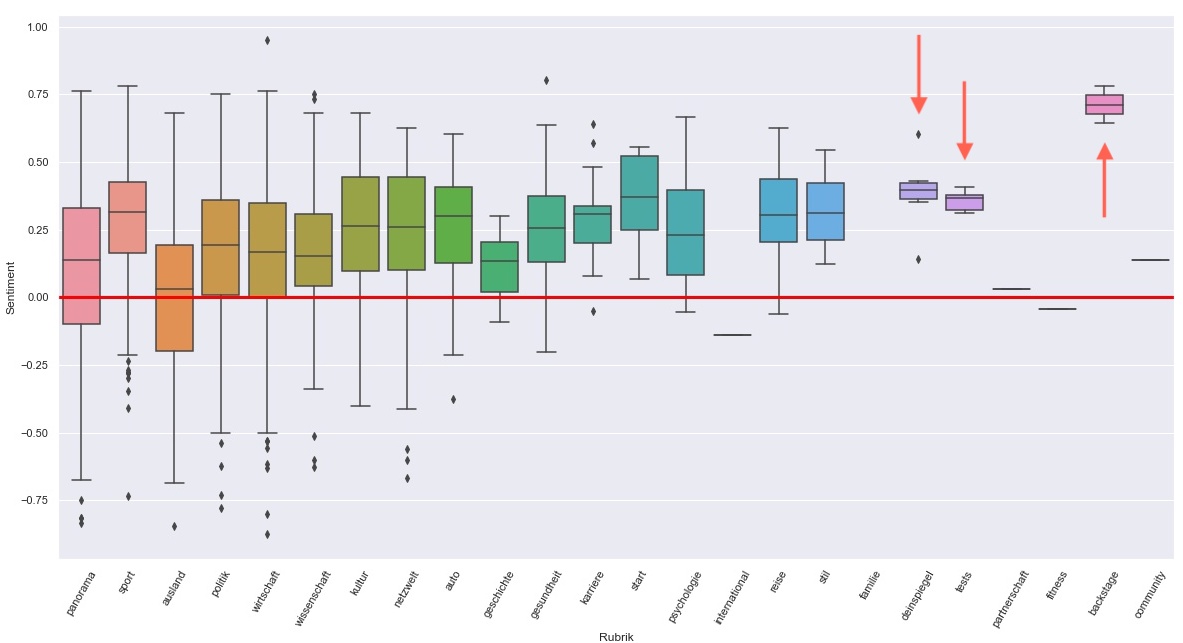
Tests is again very positive, as well as Dein Spiegel. But the crown for the most positive category goes to Backstage, a new category where the Spiegel Online Service Audio+ is advertised.
Backstage has a mean sentiment score of 0.71, beating the old Highscore from last months Tests which was 0.47.
12 Jun 2021
Intro
I downloaded all Spiegel Online articles that were published between 05/05 - 06/05/21 and ran a sentiment analysis on them. In total there are 3.585 articles for this month, including Spiegel Plus and deleted articles.
Articles per Category
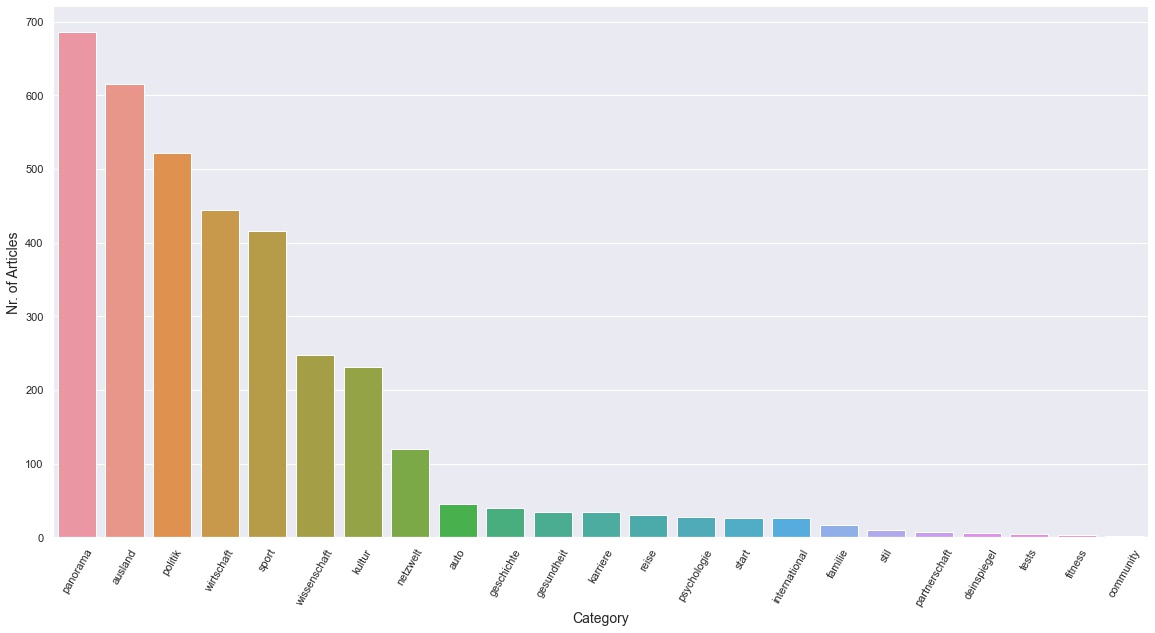
About half of all articles were published under the categories Panorama, Ausland and Politik.
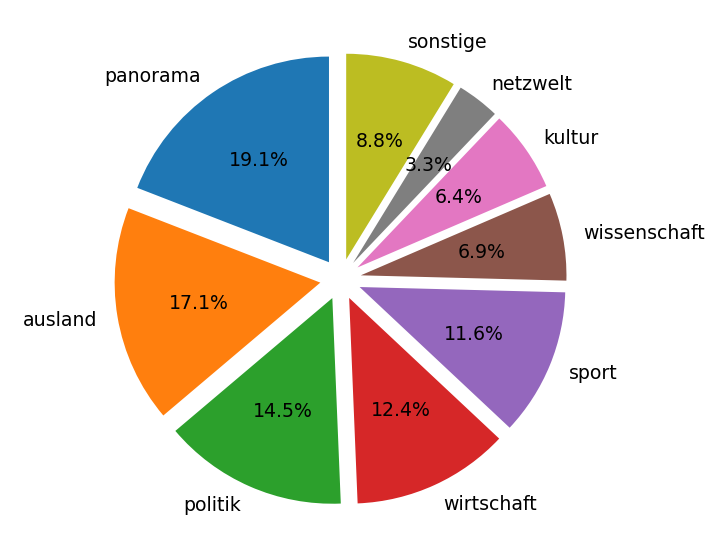
Articles per day
There seems to be a repeating pattern for the amount of articles that get published each day of the week. During the week appear more new articles than on weekends and the peak is around Friday.
On May 13th a lot less articles than expected were published, which is most likely due to it being a national holiday (Christi Himmelfahrt/Männertag).

Sentiment per Category
I wrote an AI that assigned each word in every category a sentiment score between -1 and 1. The mean of all individual scores per word resulted in a score for each article. This article score is an indicator for the overall positivity/negativity of an article.
- -1 very negative
- 0 neutral
- 1 very positive
The following graphic shows the sum of sentiments per category. An article with 0.5 Sentiment, and another one with -0.5 Sentiment would even each other out to 0. An article with 0.2 and one with -0.4 would result in -0.2.
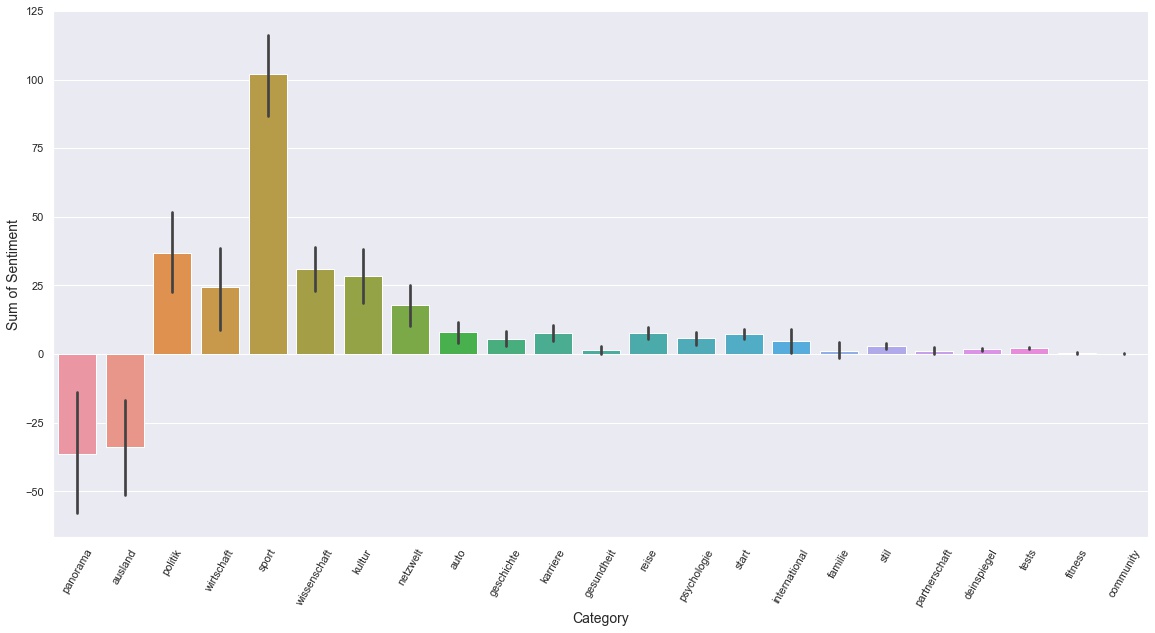
Panorama and Ausland are the only categories with negative sentiment. Sport articles are very positive and all other categories are overall positive.
Interestingly Wirtschaft and Sport have roughly the same amount of articles, but the Sentiment rating of Sport is about 4 times more positive than Wirtschaft
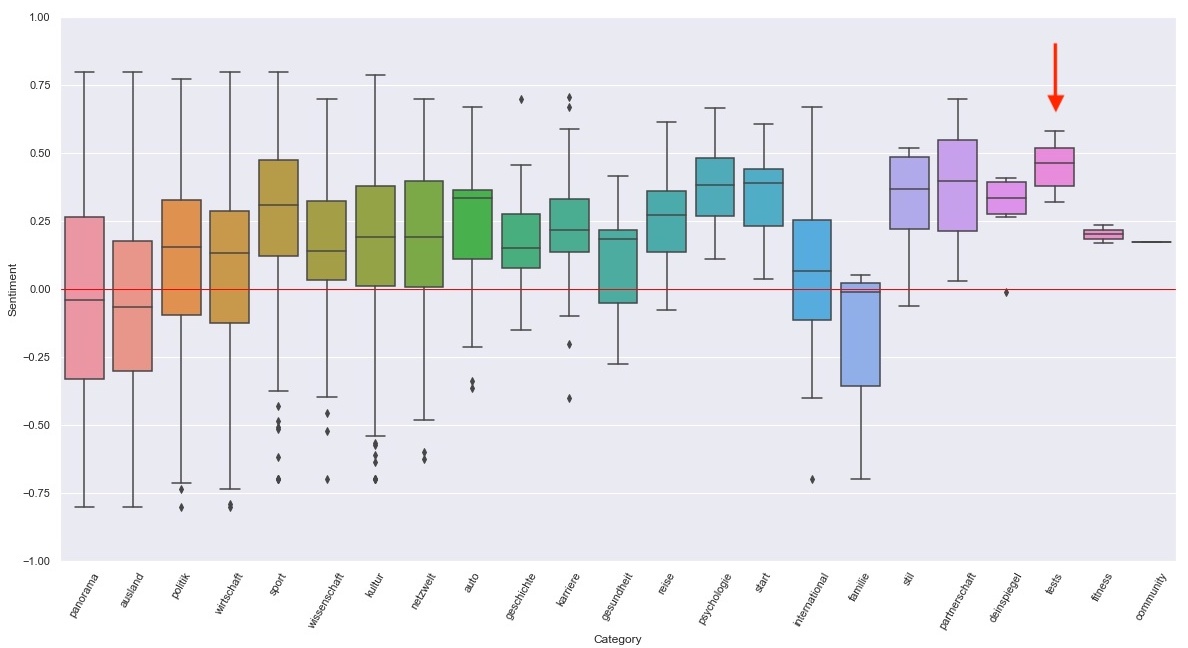
The graphic below displays the mean sentiment per category as a box plot. The least positive Article in Tests has a sentiment score of 0.32, which is still in the top 26% of most positive rated articles.
23 May 2021
This guide is about using Python and the Twitter API to get the latest tweets from a user on twitter
To setup a Twitter Developer Account, we first need a regular user Account.
- head to twitter and register your Account
Once we have a User Account, we can setup the Developer Account
After both are setup we need to create a new App under the Projects & Apps tab on the left side.
It’s important to create the Project, and then assign the App to that Project.
Creating the App allows us to get access to an API Key, which we can then use to make API calls to the Twitter Endpoints to retrieve the data.
Setup authentication with Python
To handle our API calls to Twitters Endpoint we need to import tweepy
# import the tweepy package
import tweepy
To allow tweepy to authenticate us we need to provide it with the API Key, API Secret, Access Token and Access Token Secret. I created an extra file keys.py to store those information and import them easily.
# Import keys and tokens from key.py
from keys import twitter_api_key, twitter_api_secret, twitter_access_token, twitter_access_token_secret
# Setup tweepy authentication
auth = tweepy.OAuthHandler(twitter_api_key, twitter_api_secret)
auth.set_access_token(twitter_access_token, twitter_access_token_secret)
# Initialize tweepy api
api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)
Calling the API
Creating a function and passing the name of the User we want to get Tweets from.
For easier readability I also created a constant for the Twitter URL
# Assign url constant
TWITTER_URL = "https://twitter.com"
# Function to get tweets
def get_tweets(user_name):
# Calling api.get_user(user) to get the users information
user = api.get_user(t_user)
# Searching the json for the 'id' that matches the Users name
user_id = user._json["id"]
# Get latest tweets of user with specified ID
latest_tweets = api.user_timeline(user_id=user_id,
count=1,
exclude_replies="true",
include_trs="true")
# Call the get_tweets function and provide an username as argument
get_tweets('elonmusk')
count - specifies the amount of tweets, starting with the newest
To get the actual Text message of the latest Tweet we can access the text keyword in the json:
# Loop through the latest_tweets
for tweet in latest_tweets:
# Filter out the values where the key matches 'text'
tweet_text = tweet._json['text']
# Print the value of the tweet
print(tweet_text)
For further information check the official Tweepy documentation
02 Apr 2021
In this quick guide we will explore how to get the current ISS location.
Imports
import json
import urllib.request
from keys import positionstack_api_key
Setting the Endpoints
Specifying the Endpoints as a constants to access the API
ISS_ENDPOINT = "http://api.open-notify.org/iss-now.json"
POS_ENDPOINT = "http://api.positionstack.com/v1"
Getting the Current Latitude and Longitude of the ISS
To get the current position we need to make an API call to the endpoint.
req = urllib.request.Request(ISS_ENDPOINT)
response = urllib.request.urlopen(req)
The response is in a .json format and looks like this:
{
"timestamp": 1624169097,
"iss_position": {
"latitude": "28.2089",
"longitude": "-7.2213"
},
"message": "success"
}
Read the .json and set variables for Latitude and Longitude.
obj = json.loads(response.read())
pos_long = obj["iss_position"]["longitude"]
pos_lat = obj["iss_position"]["latitude"]
Calling positionstack to convert lon/lat into a location
To turn the Coordinates into an actual location, we are calling the positionstack api and pass in the current Latitude and Longitude as arguments.
req_pos = urllib.request.Request(f"{POS_ENDPOINT}/reverse?access_key={positionstack_api_key}&query={pos_lat},{pos_long}")
response_pos = urllib.request.urlopen(req_pos)
The response comes as .json again and looks something like this:
{
"data": {
"results": [
{
"latitude": 38.897675,
"longitude": -77.036547,
"label": "1600 Pennsylvania Avenue NW, Washington, DC, USA",
"name": "1600 Pennsylvania Avenue NW",
"type": "address",
"number": "1600",
"street": "Pennsylvania Avenue NW",
"postal_code": "20500",
"confidence": 1,
"region": "District of Columbia",
"region_code": "DC",
"administrative_area": null,
"neighbourhood": "White House Grounds",
"country": "United States",
"country_code": "US",
"map_url": "http://map.positionstack.com/38.897675,-77.036547"
}
]
}
}
Reading the .json and accessing the location
obj_pos = json.loads(response_pos.read())
location = obj_pos['data'][0]['label']